
Administrator : SHO-ICHI
初めての方は、PROFILEをどうぞ。
このサイトでは、アマチュアあにめぇた・SHO-ICHIが普段やっていることなどを紹介しております。
- (´・ω・`)φカリカリ…
-

線画 -

彩色 -

Composition
【Works】「実践AI・写真・3Dからの背景起こしとか自作画像を補完する方法」第二集が発売中
2024年9月12日
既刊「実践AI・写真・3Dからの背景起こしとか自作画像を補完する方法」の第二集が発売中です
作業にかかるとどうしても更新の方が開いてしまいますね。
のっけから言い訳で申し訳ありません。まあネタがなかったのも事実ですが。
実は4月頃までは割と暇があったので、こちらのサイトを更新している余裕もあったのですが、最近また新しい仕事とかの関係で余裕がなくなってきたのもあります。
そういえば、前回告知していた「実践AI・写真・3Dからの背景起こしとか自作画像を補完する方法」の第二集が販売開始されています。
BOOTH版(PDF)、Kindle日本語版(EPUB)があります。今回は英語版はありません。英語版の出版希望があれば、著者あてリプライしてください。
今回はラフ画からAIでイラストを起こす手順がメインとなっています。
新作、頒布開始です。
— えむけぃつぅ@ギャルゲ塗り始めました (@armored_fairy) June 3, 2024
皆様のRTが頼りです。よろしくお願いします。
【実践AI】写真・3Dからの背景起こしとか自作画像を補完する方法2(Kindle版) https://t.co/1EaeaiikGK #Amazon #StableDiffusion
高解像度のBOOTH版もあります。 pic.twitter.com/oNNYtjuSNN
【Works】Amazon売れ筋ランキング1位達成
2024年4月21日
協力させていただいた「実践AI・写真・3Dからの背景起こしとか自作画像を補完する方法」がAmazonのKindleストアでカテゴリーの売れ筋ランキング1位を達成しました(棒読み)
これが送られてきたスクリーンショット。
-

Kindleストアカテゴリーの売れ筋ランキング1位達成
とは言っても、既にご存じの方もいると思いますが、Amazonの売れ筋ランキングは1時間毎に更新されますし、トータル部数というより瞬間風速的なものですので、「売れ筋ランキング1位になりました!」とか声を大にして宣伝するようなものではないです。
ついでに言うと、全く関係がなくても登録数が少ないカテゴリーを選んでエントリーすれば簡単に1位になれますので、そうしたプロモーションをする本もあるようです。まあ自分としては逆効果じゃないかとは思いますが。
ただし、内容に見合ったカテゴリーの中だと自費出版で売れ筋ランキング上位に入れる書籍が多くないこともまた事実なので、ここは素直に喜ぶべきところでしょう。
BOOTH版(PDF)、Kindle日本語版(EPUB)、Kindle英語版(EPUB)があります。英語版はKindle専売になりますが、他のストアで日本語版の出版希望があれば、著者あてリプライしてください。
最後になりましたが、続編となる第二弾が予定されています。こちらでもお手伝いさせていただく予定です。
と言うわけで第二弾準備中。 https://t.co/LvhAyFEVfI
— えむけぃつぅ@ギャルゲ塗り始めました (@armored_fairy) April 15, 2024
【Works】実践AI・写真・3Dからの背景起こしとか自作画像を補完する方法
2024年2月9日
こちらの書籍のお手伝いをさせていただきました。
スタッフクレジットは自分の都合もあって名前の掲載はありませんが、画像の提供とか協力しています。
BOOTH版(PDF)、Kindle日本語版(EPUB)、Kindle英語版(EPUB)があります。英語版はKindle専売になりますが、他のストアで日本語版の出版希望があれば、著者あてリプライしてください。
Kindle版
kindle版、販売開始。
— えむけぃつぅ@ギャルゲ塗り始めました (@armored_fairy) February 9, 2024
「本書では、Stable Diffusion Web-UIを使って背景を写真から起こしたり、イラストのキャラと写真を組み合わせて出力する方法を色々と解説しています。」
【実践AI】写真・3Dからの背景起こしとか自作画像を補完する方法https://t.co/MXyMSB1peb #StableDiffusion #Amazon
【Works】NVIDIA A4000のフルチューン
2023年10月15日
この記事に書いてある内容を実行する場合は全て自己責任でお願いします。
ローカル環境でAI画像生成を行うには高性能グラフィックカードが不可欠ですが、大量の連続生成やアップスケールではGPUやVRAM温度がすぐに100度を超え、サーマルスロットリングによる性能低下が毎回のように起こります。
このため連続生成すると、704x512の画像1枚生成するのに最初は3秒程度で生成しますが、すぐに6~7秒掛かるようになり、1280x1760のアップスケールでは4分弱、2560x3620のアップスケールだと30分くらい掛かっていました。流石にこれは熱対策しないとどうもならんと思いまして、内部サーマルパッドの貼り替えと再グリスをやってみました。
難易度としては、3.5インチHDDをスムーズにバラせるくらいのスキルでしょうか。やったことがない方は、2~3台、不要のHDDをバラしてみると練習になっていいかも知れません。
詳しいやり方はこちらの動画を参照して下さい。
今回使用したツール
-

今回使用したツール
- 【親和産業(グリス)】シミオシ OC Master SMZ-01R
- 【Thermalright(シリコンサーマルパッド)】85x45x1mm
- 【Thermalright(シリコンサーマルパッド)】120x120x0.5mm
- 精密ドライバーセット
- トルクスレンチ T6、T8
- グリス塗り用のへら、模型用ラジオペンチ、カッター、ハサミ、ピンセット、アルコールウェットティッシュ、ダストブロアーなど
-

内部ヒートシンクを外したところ
まず、フロントのカバーとヒートシンクを外します。
中は意外とホコリが溜まっていたりするので、ダストブロアーで掃除します。中央のチップがGPUで、写真はGPUこびりついたグリスをアルコールティッシュで拭き取った状態です。
詳しいバラシ方は動画を見ていただくとして、ここでは自分がハマリかけたポイントを書いておきます。
1. メイン基板の外し方
写真は基盤を外した状態ですが、ネジを全て外し基盤を分離しようとした時に、基盤のカド付近に力を加えてもなかなか外れません。
動画にあるように、PCI-Eの端子部分に力を加えてやると簡単に外れます。外れる時はパカっと気持ちよく外れるので、なかなか外れない時は力を入れる場所が違っています。力を加える場所を間違えると基盤を破損しかねないので、動画でよく確認して下さい。
-

基盤を外したところ
2. サーマルパッドの切り方
基盤を外した写真では、元のサーマルパッドが見えています。これを剥がして新しいサーマルパッドと交換していきます。
基板の黒い8枚のチップがVRAMで、この場所にサーマルパッドが当たっていたことが分かりますね。
動画にはサーマルパッドの詳しいサイズが書いてありますが、サイズ通りに切ってから貼ろうとすると、だいたい失敗するので、大きめに切って所定の位置に貼り付け、後からカッターで余分な部分を切り取ります。貼る場所は全て金属なので、カッターを当てたところで問題はありませんし、前の貼り跡を目印にカッターを当てるとだいたい動画のサイズ通りになっています。
1mm程度サイズが大きくても大丈夫です。むしろ小さい方が心配です。サーマルパッドの役割は、基板のチップと金属フレームの隙間を埋めてチップの熱を金属フレームに逃がしてやることですので、厚みの方が重要です。今回の内部サーマルパッドの厚みは1mmですが、これを仮に0.5mmにしてしまうと、隙間が埋まらず熱がチップに溜まって暴走し、OSが起動しないなどのトラブルになるのです。
つまるところ、液状グリスの働きと同じでグリスもシリコンですから、固形化したグリスと言ってもそれほど間違いではありません。
3. サーマルパッドの扱い方
-

ヒートシンクに0.5mm厚のサーマルパッドを貼ったところ
写真は、内部ヒートシンクに0.5mm厚のサーマルパッドを貼ったところですが、0.5mm厚のサーマルパッドはとても扱いにくいです。
元の大きさは120x120mmですが、そのままヒートシンクに貼ってあとからカッターで余分な部分を切り取ります。
一見無駄なようですが、たぶん一番失敗の少ない方法です。
今回使用したThermalrightのサーマルパッドは表に青い保護シート、裏に透明フィルムが貼ってあるのですが、この透明フィルムがとても剥がしにくいです。
端からゆっくり剥がしていくには違いないのですが、剥がそうとするとカドがボロボロと崩れるので思わず手を止めてしまいがちです。
正解は「最初に崩れるのは気にせず、そのままゆっくり剥がす」です。
剥がれ始めるとすんなり剥がれるので、最初の破損は気にしないようにしましょう。
これがあるから、サイズ通りに切ってから貼るのは失敗しやすいのです。
ちなみに両面放熱ですので、裏表は関係ありません。
熱対策の効果
さて、元通りに組み立てたら、さっそくAI画像生成をやってみましょう。
まず、704x512の連続生成は100枚以上連続生成させても、GPU温度は85度以上にならず、生成時間も約3秒を維持していました。
次に1280x1760へのアップスケールでは、生成時間平均44秒ぐらいを維持して、GPU温度も最高で91度でした。約6倍のスピードアップ。
最後に2560x3620へのアップスケール。流石に終わりの方ではGPU温度も92度まで上がりましたが、生成時間は4分28秒。やはり約6倍の速度です。
改めて熱対策の効果は絶大であることを確認できましたので、グラフィックカードの発熱と生成速度の低下にお悩みの方は熱対策が必要だと言うことです。ただ、今回のような内部サーマルパッドの貼り替えとかは難易度は高いので、多少の効果は期待できそうなバックプレートのヒートシンクとかも検討してみるといいかと思います。
【Works】光源と明度と構図の制御
2023年9月17日
グラデーションマットのimg2img
前回、白いマットからモノクロ画像を作る方法を紹介しましたが、その応用技が開発されたようです。
i2iのDenoising strength:1で出力するところは同じですが、白マットの代わりにグラデーションを使いカラー画像を出力します。
この手法の面白いところは、グラデーションの明るい部分がそのまま光源方向になり、明暗の境界に沿ってキャラが作成されやすくなるので、構図も制御しやすい点でしょう。
また、室内だと、暗い部分には窓が形成されにくくなります。一般にAIで背景を出力すると全方向に窓が出来やすいので、窓の生成を光源方向に限定出来るのは結構便利だと思います。
※ 光源を制御できないと全方向に窓が出来やすいとも考えられます。
-

グラデーションマット -

グラデーションマットからDenoising strength:1で生成
このグラデーションを縞模様にしてみますと、同じプロンプトとseed値なので似たような構図になりますが、全体の明度が上がります(この縞模様は、Illustratorのブレンド機能で作っています)。
-

縞模様のグラデーション -

縞模様のグラデーションからDenoising strength:1で生成 -

白画像からDenoising strength:1で生成
白い部分の面積が明度に反映されるようで、白マットから出力すると白トビしたような絵になります。
今回使ったプロンプト
全て共通のプロンプトです。
- parameters
- <lora:Silicon-landscape-isolation:1>,<lora:flat:-0.5>,masterpiece,best quality,excellent anime painting,extremely detailed thick drawing,vivid saturation,high brightness,on sunny days,artstation,pixiv,danbooru,looking away,BREAK 1girl,solo,cute girl,hatsune miku,hatsune miku's hairstyle,medium hair,hair between eyes,(close eyes:0),happily,(close mouth:0),BREAK Western-style living room,white wall,BREAK small breastsBREAK detached Sleeve,tie
- Negative prompt: nsfw,masterpiece,(bad-hands-5),((bad hands,fewer digits,bad anatomy,mutated limbs)),(extra limbs:1.2),(EasyNegativeV2),(negative_hand-neg),(verybadimagenegative_v1.3),3d,text,logo,caption,((monochrome)),((grayscale))
- Steps: 28, Sampler: Euler, CFG scale: 10, Seed: 2067310822, Size: 512x704
プロンプトで構図や明度、光源を制御するのは結構難しいのですが、この方法を併用すれば、イメージに沿った画像を生成しやすくなりますね。
【Works】モノクロ画のAI出力
2023年8月6日
その発想はなかった。
Stable Diffusionでモノクロ画をきれいに出力するのは結構苦労するのですが、素晴らしい発想の持ち主はどこにでもいるもので、実に簡単な方法で実現できました。
普通にt2iでW:512、H:704で出力(左)したものをi2iへ送りプロンプトを少し変えます(「プロンプトの補正」参照)。
主な補正は、描画をink drawingに、brownなどの色指定を消して、背景をwhite backgroundとsimple backgroundに変更、NegativeにあったmonochromeとgrayscaleをPositiveに移動、といったところです。その他の細かい指定はt2i出力のプロンプトによって変わります。
i2iに送られた画像をW:512、H:704の真っ白な画像で置き換え、Denoising strength:1で生成すると綺麗にモノクロ化します(右)。
※ 掲載している画像はControlNetのtileでアップスケールしています。
-

まずはt2iで普通に出力 -

白画像からDenoising strength:1で生成
この手法を考えついたAI術師のヒツジさん。
うおおおおッ、白紙のpngデータに"Denoising strength"を1でi2iすると、かなりきれいな線画でイラストが生成できるテクニックを見つけて、興奮してるううううッ! pic.twitter.com/TLSxaajOsB
— ヒツジ / HITSUJI(AIマンガ家) (@jikutakatsuo) July 13, 2023
センシティブ警告が出てますが全然センシティブじゃないです。相変わらずtwitter(X)のセンシティブ基準はよく分からん。
プロンプトの補正
カラー画像の出力プロンプト。
- parameters
- <lora:Silicon-landscape-isolation:1>,<lora:flat:-0.3>,masterpiece,best quality,excellent anime painting,extremely detailed thick drawing,vivid saturation,high brightness,on sunny days,artstation,pixiv,danbooru,looking away,1girl,solo,cute girl sitting on the brown sofa,arms support,green hair,bery long hair,hatsune miku's hair style,hair between eyes,blue eyes,(close eyes:0),smile,happily,blush,embarrassed,parted lips,(close mouth:0),Western-style living room,white wall,bay window,small breasts,face,from above,looking at viewer,((maid,bare shoulders,bowtie,detached collar,detached long sleeve,white maid headdress,white apron,dress,cleavage,skirt hold,black thighhighs)),(POV)
- Negative prompt: masterpiece,(bad-hands-5),((bad hands,fewer digits,bad anatomy,mutated limbs)),(extra limbs:1.2),(EasyNegativeV2),(negative_hand-neg),(verybadimagenegative_v1.3),3d,text,logo,caption,((monochrome)),((grayscale))
- Steps: 28,Sampler: Euler,CFG scale: 7,Size: 512x704
モノクロ出力用に補正したプロンプト。
- parameters
- <lora:Silicon-landscape-isolation:1>,<lora:flat:-0.3>,masterpiece,best quality,excellent ink drawing,extremely detailed thick drawing,artstation,pixiv,danbooru,looking away,1girl,solo,cute girl sitting on the sofa,arms support,bery long hair,hatsune miku's hair style,hair between eyes,smile,happily,embarrassed,parted lips,white background,simple background,small breasts,face,from above,looking at viewer,maid,bare shoulders,bowtie,detached collar,detached long sleeve,maid headdress,apron,dress,cleavage,skirt hold,thighhighs,(POV),((monochrome)),((grayscale))
- Negative prompt: masterpiece,(bad-hands-5),((bad hands,fewer digits,bad anatomy,mutated limbs)),(extra limbs:1.2),(EasyNegativeV2),(negative_hand-neg),(verybadimagenegative_v1.3),3d,text,logo,caption
- Steps: 28,Sampler: Euler,CFG scale: 7,Size: 512x704
AIは絵を描けなくても自分のイメージを形に出来ますが、絵を描く訓練をした人でなければ出来ない、思いつかないこともたくさんあります。
お気に入りの絵が出力できる、モノクロが出力できる、で終わりではありません。そしてコンテンツの作り方が根本的に変わる、そんな気がしています。
【Works】AI出力でキャラを固定する
2023年6月18日
LoRAを使ったキャラの固定
AIイラストの弱点の一つに、「毎回同じキャラを出力するのが難しい」というのがあります。
そこで話は凄く端折りますが、追加学習、LoRAを使ったキャラ固定方法について書いてみます。
LoRAとは、大雑把に言うと十数枚程度の画像を追加で学習させるだけで学習させた特徴を出力に反映することができる補助モデルのことです。
特定の作家の画像を使って本来存在しないシーンを作り上げたり出来るので色々と問題になっているのですが、逆に言えば問題になるほど優れた技術とも言えます。
詳しい作り方は省きますが、こちらの記事には大変お世話になりました。
制服姿のミクさんを固定出力するためのLoRAだと、こんな感じに出力できます。
-

同一プロンプトでもキャラと制服固定 -

中指立てるの禁止 -

一括出力ポン出しもok
この出力画像は同じプロンプトで出力したものです。
- parameters
- <lora:mkl_sleeve_mz:1>, ((masterpiece, best quality)), excellent anime painting, extremely detailed thick drawing, vivid saturation, high brightness, on sunny days, 1girl, solo, cute girl, (hatsune miku's hairstyle,green hair,long hair,very long hair,twintails,school uniform,serafuku,sailor collar,white sailor collar,vest,blue vest,bowtie,yellow bowtie,shirt,white shirt,long sleeves,skirt,blue skirt,pleated skirt),BREAK Streets lined with old buildings background, artstation, cover illustration for light novel, pixiv, danbooru, <lora:Silicon-landscape-isolation:1>
- Negative prompt: <lora:mkl_sleeve_mz:1>,nsfw, (bad hands, fewer digits, bad anatomy, mutated limbs), (extra limbs:1.2), (EasyNegativeV2), (negative_hand-neg), (verybadimagenegative_v1.3), 3d,text,logo,caption, ((monochrome)), ((grayscale)),white background,simple background
学習画像は16枚で、前回の要領で作ったものをベースにしてControlNetのreference_onlyとopenposeを使ってプロンプトを変えながらバリエーションを作ります。なお、制服デザインは自分ですので念のため。
-

lineart_animeから手描きで線画を描いてAIで塗る -

reference_onlyとopenposeでバリエーション -

背後のデザインも忘れずに
もちろんそのままではあちこち違っているので同じデザインになるようレタッチしますが、全部描くよりも遙かに短時間で済みます。
そのレタッチにしても、そこそこラフに塗ってもi2iによる再出力で綺麗に塗り直してくれるので、クリーンアップツールとしてもAIは優秀ですね。
実際、一枚絵の品質向上よりも同じキャラの大量生産ができればAIの強みになり得ると思いましたし、マンガやゲームのように何枚もの絵で構成されたコンテンツはAIが主力になっても不思議はありません。
まあ少なくとも、AIなら締め切りを守らないってことだけはありませんからね。
【Works】AIを使った作画手順を考える
2023年5月7日
Extraに追加しました。
前回に引き続き画像生成系AIの話題です。
作画を行う場合、画像生成系AIを使った汎用的な方法論に落とし込む手順をExtraに掲載しましたので、ご覧になって下さい。
デモムービー制作にしてもデザインにしても素材がなければ成り立ちません。オリジナルの動画を作ろうとすると、この素材制作からやらなければならないので、ものすごく時間が必要ですが、AI技術の進歩は、この素材作成時間を短縮できるものとして期待しています。
前回の背景制作も、その後、モデルやサンプリング方式、アップスケールやControlNet設定、画像補正用LoRAの導入など色々と試していくうちに、どうやら実用レベルの出力ができるようになってきたのではないかと思います。
-

桜と鉄路
- parameters
- ((masterpiece, best quality)),excellent anime painting, on sunny days, blue sky, Graveled railway track,green grass, mountain, no_humans, outdoors, river, scenery, tree of cherry blossom, artstation, cover illustration for light novel, pixiv, danbooru, SIGMA 24 mm F1.4, ISO 100, <lora:flat:-1>
- Negative prompt: (EasyNegativeV2)
- Steps: 20, Sampler: DPM++ 2S a Karras, CFG scale: 7, Seed: 406455872, Size: 704x512, Model hash: 17277fbe68, Denoising strength: 0.7, ControlNet 0 Enabled: True, ControlNet 0 Preprocessor: lineart_anime, ControlNet 0 Model: control_v11p_sd15s2_lineart_anime [3825e83e], ControlNet 0 Weight: 1, ControlNet 0 Starting Step: 0, ControlNet 0 Ending Step: 1, ControlNet 0 Resize Mode: Crop and Resize, ControlNet 0 Pixel Perfect: False, ControlNet 0 Control Mode: Balanced, ControlNet 0 Preprocessor Parameters: "(512, 32, 200)", Hires upscale: 2, Hires steps: 20, Hires upscaler: 4x-UltraSharp
素材を扱うのに作画や塗りの技術が必要なのは当たり前で、描くのがAIだったとしても、結局絵を描く技術そのものが不要になる訳ではない、ということは覚えておいた方がいいかも知れませんね。
【Works】画像生成系AI、Stable Diffusionによる背景生成
2023年4月16日
AIを知らずにAIには勝てない。
孫子の兵法ではありませんが、一度加速を始めた技術を止めることはまず不可能ですし、それよりは上手い付き合い方を早く見つけた方が生産的だと思うので、Stable Diffusionを導入してみました。
自分は絵描きのはしくれで、動画師であり、3D屋でもありますが、AI絵は、絵描きの視点から見ると努力もなしに絵が描けたように見えてしまうので忌避感があることは理解できますけど、動画や3Dの視点から見ると、AIはAfterEffectsのプラグインや3D景観ジェネレーターと構造的に大差ないと感じており、それほど違和感がありません。
例えばPsunamiプラグイン(Eleanor DEMOページ)では、波や大気のパラメーターを設定してリアルな波の描写を可能にしますし、World Builder(Polyphonica12 DEMOページ)はセグメントを指定した場所に大地や樹木を生成してくれます。
波や樹木をモデリングすることなしにランダムなバリエーションをseedで生成するあたり、画像生成系AIとよく似ています。
3Dやってる人がこれらのツールに忌避感を示すことはまずありませんし、生成されたAI画像も、リアル系の画像はその気になれば3Dで再現可能ですので、ツールの一つと認識するのはそれほど的外れではないと思います。
そんな訳で画像生成系AIもそのうち描画ツールの一つになっていくのではないかと楽観しているところです。
さて、PsunamiプラグインやWorldBuilderなどを使っていることからも分かるように、背景作成というのは非常に面倒くさいです。
前回紹介した新海監督作品から背景を取り除いたらあの映像は成立しないと思うので、個人的に新海監督は、背景映像作家という認識ですが、2Dで描くにしろ3Dで作るにしろ、普段は気にもとめないのに作り込まれていないと全体のクオリティが低いように見えてしまうのが背景です。
漫画を描いていた時代、とある同人紹介本では「背景が素敵」とかコメントされただけでキャラに言及されず凹んだ苦い思い出があるくらい、昔から背景には思い入れがあります。
流石に360度回転するような全方位背景はまだ無理ですが、1枚絵の背景ならば汎用性が高いので、今回は写真からAIで背景画を作ってみました。
インターフェースはStable Diffusion Web UIで、モデルはStable Diffusion1.4を使っていますが、AIをローカルで動作させる方法や個々の操作方法については詳しく書きませんのであしからず。
まず、元になる写真を用意します。
遠野市綾織付近の猿ヶ石川沿いにある桜並木ですが、自分が撮ってきた写真を使っています(ここ重要)。
不要な部分を削除するなどレタッチした写真をimg2imgのCLIP解析でプロンプトを生成し、描画方法(Painting)や彩度(saturation)、Negativeなどを設定したプロンプトにします。
txt2imgでプロンプトを入力し、ControlNetに元画像を放り込み、Cannyモデルで画像を生成します。
-
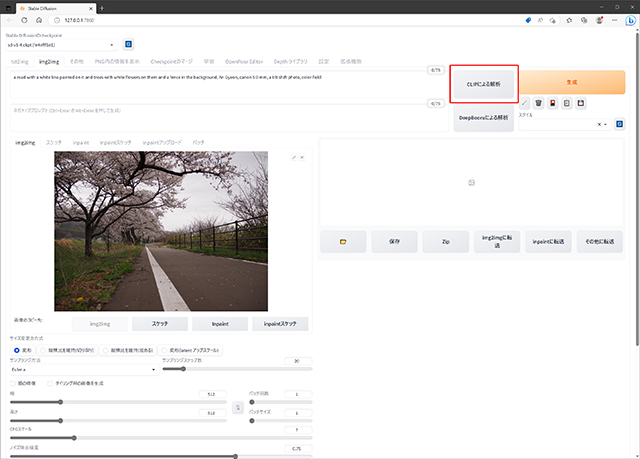
元写真からプロンプト抽出 -
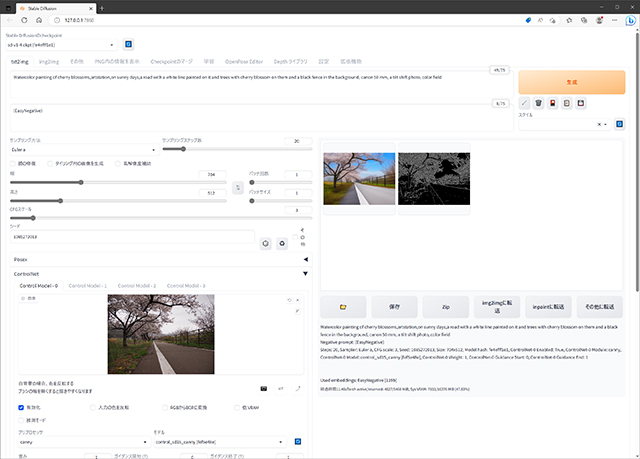
ControlNet Cannyで画像生成
注意点というほどではありませんが、元画像は大きいまま(今回は4032x3024)Web UIに放り込んだ方が良いようで、小さい画像だと読み取り精度の問題なのか、プロンプト解析やCannyの線画抽出が大雑把になってしまうようです。
-

元画像写真 -

cannyで抽出された線画 -

生成された桜並木の画像
今回の生成パラメータ(PNG記録情報)はこんな感じ。
- parameters
- Watercolor painting of cherry blossoms,artstation,on sunny days,a road with a white line painted on it and trees with cherry blossom on them and a black fence in the background, canon 50 mm, a tilt shift photo, color field
- Negative prompt: (EasyNegative)
- Steps: 20, Sampler: Euler a, CFG scale: 3, Seed: 1085272013, Size: 704x512, Model hash: fe4efff1e1, ControlNet-0 Enabled: True, ControlNet-0 Module: canny, ControlNet-0 Model: control_sd15_canny [fef5e48e], ControlNet-0 Weight: 1, ControlNet-0 Guidance Start: 0, ControlNet-0 Guidance End: 1
まあこれだけだと潤いもないので、ミクさんの画像もおいておきます。
-

お座りミクさん -

寒いですねミクさん -

ちびミクさん
-

朝ちゅんミクさん -

お花見ミクさん -

競泳水着のミクさん
ただ、どうしても画像が小さくなりがちで、商用レベルで使えるような解像度にするにはハードウェアの進歩も必要ですし、実用的になるには少し時間が必要かも知れません。
AIの技術はものすごい勢いで進歩しており、最新の技術を追いかけるだけで時間が飛んでしまうので、ある程度のところで安定した技術を使っていくしかありません。
先週出た技術で苦労していた部分が今週には解決していたりする、なんてことは日常茶飯事ですが、それでも動画、アニメーション、3D、そしてイラストは同じ創作でも異なった技術体系から出来ているので、複数のAIを組み合わせれば現在でも出来ますけど、これらを一貫して生成するAIはしばらく出来るとも思えません。
何せ、現在は各AIが覇権争いの真っ最中で、協力し合うようになるにはしばらく時間がかかるでしょう。
ブラウザ戦争やモバイルOS戦争に続く久々にやって来た動乱の時代。そんな時代だからこそAIを使う価値があるとも言えます。
ただ、いずれはAI技術も標準化するでしょうし、一貫制作AIができれば自分も廃業ですが、その頃にはムービー屋なんてものはいなくなっていると思うので、今は行く末を見守るとしましょうか。
【Cinema】「すずめの戸締まり」と12年前の記録
2023年3月11日
(注:後半に12年前の被災地を撮影した画像があります。)
新海誠監督の最新作「すずめの戸締まり」をもう見ましたか。
自分は遅まきながら、今日3月11日、「すずめの戸締まり」を見てきました。
見終わった直後の第一声は「いわてマンガプロジェクトの担当者は即刻、新海監督とコンタクトすべき。」でした。
自分たち自主制作映像クラスタにとって新海監督は一つの完成形でもあるので、まあ神様みたいなものです。時には祝詞で封印したくもなるのですが、残念なことに要石がないと難しいと思われます。
実のところ、「君の名は。」が完成した直後に、(たぶん新作までに3年ぐらいの余裕があるので)新海監督を岩手の商品プロモーションに担ぎ出そうと親会社に企画を提出したことがあるんですが、却下されました。「すずめの戸締まり」が公開されて、今頃「失敗した」と思っているかも知れませんが、既に遠く離れた自分の知ったことではありません。
まあ、皆さんの会社にも隠れてネット活動をしている「野生のプロ」はいるものですが、彼らはだいたいリアル社会で目立つことを嫌うので、単なるパソコンオタクとして認識されている場合が多いと思いますけど、たぶん色々な意味で人件費を無駄にしていますよ。
閑話休題。
あの東日本大震災を扱ったという「すずめの戸締まり」を、図らずも3月11日に見に行くことになってしまいました。
新海監督の作品を劇場で見るのは、久しぶりだったりします。大抵、配信だったり円盤だったりで、それでも満足していましたから。
けれど、以前からこの作品だけはハコで見よう、そう思っていました。新海監督の目に震災はどう映ったのか、震災後の12年をどう捉えているのか。それが知りたかったから。
2023年3月11日、東日本大震災から12年が経ちました。あの大災害を身近に体験した身としては、この日は毎年、特別な思いを感じる日となっています。
繰り返し語られる「12年前」という言葉が胸に響きました。
公式サイトによれば「扉の向こうから来る災い」、神話風に言えば「禍津日(まがつひ)」でしょうか。日本は古来から地震と噴火に苛まれた土地なので、一般には大災害を荒ぶる神々として語り伝えていると言います。
そうした日本の呪術的背景と、現代風学園もの、そして震災への哀悼の意を組み合わせ、新海監督の美しい背景描写をBGVに日本を縦断するロードムービー。
朝の支度や気象などの自然現象の描写は「はるのあしおと」や「eden*」から演出の方向性が変わっていないので古くからのファンには安心感があります。
ネタバレなしの大雑把な感想はそんな感じでした。
以前から、自分も震災復興関連の仕事をしていると言う話はしていますが、実は震災から約50日後、沿岸を歩いて、この目で現地を見てきているんです。
ただ、やはり震災からそれほど時間が経過していないうちに現地の写真を掲載することには抵抗があり、今日まで未公開でしたが、「すずめの戸締まり」を観て、ああ、これは公開しなければいけない、と思いましたので、2011年5月3日に撮影した記録写真を公開します。
大船渡湾東側
-

大船渡湾奥の被災した家屋 -

津波に流され引き上げられた車両 -

崩壊した大船渡湾湾口防波堤遠望 -

堤防に乗り上げた作業船
防波堤に乗り上げている船舶は珍しくありません。原型を留めている車両は引き上げられ、並べられていました。
門之浜湾
-

津波に引き倒された防波堤 -

引き波で倒されると海側に向かって倒壊 -

倒壊家屋のがれきと基底部が剥き出しの防波堤 -

海岸から目測1kmに渡って家屋が倒壊
防波堤というのは押してくる波の力には強くても、いったん防波堤を越え、海に向かって波が引いていく力には脆いようで、この付近の防波堤はみな、海側に向かって倒れています。
陸前高田市高田松原付近
-

被災した大型施設遠望 -

体育施設など多くの公共施設が被災 -

泥流に沈む建築群 -

津波で一般家屋が見渡す限り消失
陸前高田市は気仙川の扇状地に広がる町なのですが、その殆どが流されており、見渡す限りの更地で言葉を失い、しばらく呆然と立ち尽くしていました。
「すずめの戸締まり」始末
最後に一つだけ不満を。
作中、三陸鉄道の(たぶん)36-700系が出てくるのですが、監督らしくない曖昧な車輌描写でした。
-
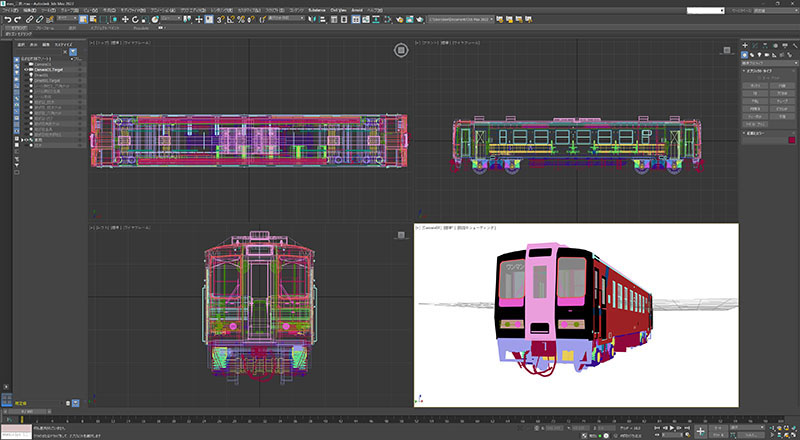
三陸鉄道の36-100系3Dモデル
自分は、新海監督の鉄道描写に大きく影響を受けて三陸鉄道の36-100系モデルを殆ど偏執的なまでに組み上げたくらいですから、もう少し作り込みを見せてほしかったな、と。
【Works】絵描きとしてのStable Diffusion利用法
2023年2月26日
画像出力AIの使い方を考える。
-
Stable Diffusion Web UI
昨年8月頃からMidjourneyやStable Diffusionなど画像生成AIが一気にブレイクした感があります。
SNSにはAI絵師(AI術師)の生成物が溢れ、興味を示す絵師さんもいらっしゃいます。
自分も実際に使ってみましたが、お手軽に品質の高い(高そうな)絵を出力することが出来るので、中途半端な絵しか描けない自分は凹まされた気がしました。
ある日ふと思いついて自分でラフ画を描き、Stable Diffusionのimg2imgを使って出力させてみました。
プロンプトは「キュートなアニメ顔と瞳の美少女」みたいな感じで入力し、Denoising strength(ノイズ除去強度)を0.38に抑えて出力してみたところ、ラフ画をクリーンアップして、より可愛らしい感じの絵を出力してくれました。
随分と前から旧い絵柄をどうにかしたいと思いながらも上手くいかずに悩んでいたのですが、出力された絵を見て「ああそうか、こういう風に修正してやればいいのか。」と気が付き、「じゃあ現代風の彩色方法も練習しよう。」と思い立ちました。
彩色自体は、以前から仕事でレイヤー付きの素材をたくさんお借りしているので、なんとなくやり方は分かるのですが、下絵や構図はStable Diffusionを使います。
-

ラフ画からイメージに近い絵を生成
まずざっとキャラクターを描き、Stable Diffusionに放り込みます。
ガチャを繰り返して何枚か自分の絵柄に沿っていそうな絵を選び出し、その絵を手本として下描きをします。
クリスタや液タブは元から所有していますし、アニメーション作画もやっていたので、線を引いたり塗ったり色調補正したりは慣れたものです。
一応仕上げまで塗り終わってみると、まだまだ拙い部分はありますが、後は繰り返して慣れるだけだと思いました。
-

AI生成した画像を見本に下絵を描く -
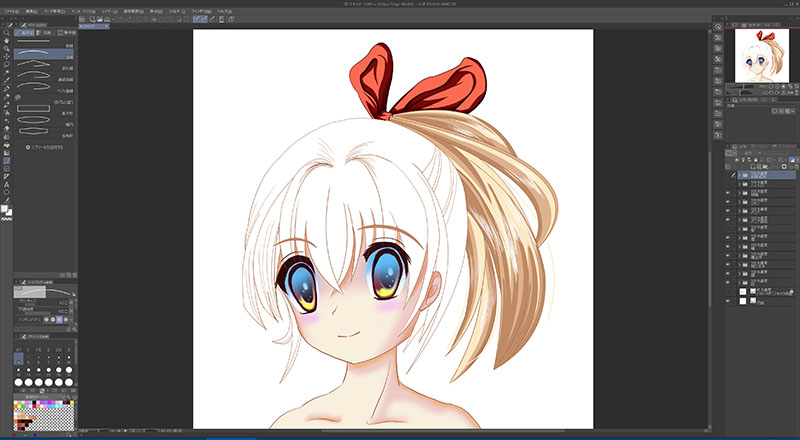
いわゆる”ギャルゲ塗り”で彩色 -
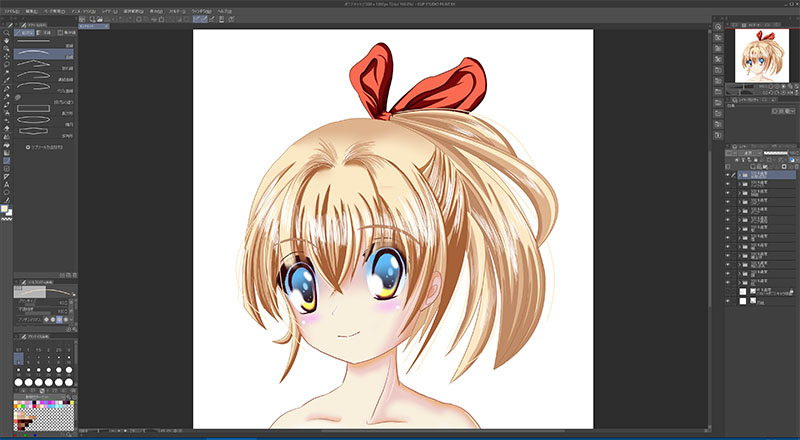
一応は完成
グラフィッカーにでもなるつもりか、とか言われそうですが、現在作りたい動画には多くの描き下ろしが必要になりそうなので、こうした練習が必要になったと言うところです。
追記
AI画像の著作権について、2月24日のニュースで「米著作権局、Midjourneyで画像生成したコミックブックの著作権取り消し」なんて記事が出ておりましたが、AIで出力した画像は多少手を加えた程度では著作権を認めない判断、「Midjourneyの画像生成はユーザーによるコントロールではなく、出力をユーザーが予測できないという点において、アーティストやライター、フォトグラファーが使用するツールとは同じではない」としています。
ソース元:「米著作権局、Midjourneyで画像生成したコミックブックの著作権取り消し」|マイナビニュース
このコミックブックでは「文章およびビジュアル要素の選択、調整、配置」、つまり編集部分には著作権が適用されるようなので、画像だけが著作権を主張できない出版物くらいの扱いと言うことでしょうか。
Midjourneyで出力した絵は加筆修正、プロンプトや画像選択など人が行う要素があるので著作権がないとまでは言えませんが、そのままでは著作権で保護されるレベルではないと言うことのようです。
今回のように参考画像を出力する使い方だとおそらく問題ないので、まあ自分にとっての画像生成AIは、さしずめ「高度な画像検索」と言ったところでしょうか。
追記2
将棋の世界では、AIにプロ棋士が負けることはあるけど、それでプロがいなくなったりはせず、むしろAIを研究や局面検討に利用するようになっています。
では絵描きの世界ではどうでしょう。
自分は、絵を描く人のレベルによってAIの使い方が変わると思っています。
まるで描けない人は、イメージを言葉にしてtx2imgでAI画像を出力する。
デッサンや色彩設計が苦手な人は、AIでポーズや配色を出力させることが出来るでしょう。
自分のようにある程度は描けるけど一線級とはいかない人の場合、今回のようなAIに絵柄を矯正してもらう使い方があります。
一流以上の人の場合、残念ながら自分には想像が出来ませんが、それほど必要はないかも知れませんね。
なぜなら、そうした一流の人々の絵ならば既に学習データになっているでしょうから、AIはそれ以上の絵を出力することは出来ませんし。
人は試行錯誤して前へ進むことができますが、AIは試行錯誤が出来ないので大量の学習データから最適な結果を出力するのです。
普通の人はそんな大量の学習をこなすことは出来ませんが、試行錯誤によって最適な結果を選び取ることが出来ます。
これは構造、アーキテクチャの違いであって、AIは学習していないものは生み出すことは出来ませんが、人は学習してからであればどんなものでも出力することはできます。
AIに出来て自分には出来ないこととは、つまり自分が学習していないことな訳で、ある意味当たり前のことです。
同じAIでも、ChatGPTは(現在のところ)画像出力が出来ませんが、絵の描けない人が絵を描けるようになることは可能です。
つまり、AIとは技術でありツールであることから、使い方はその人次第、という至極当然の結論になるのだと思います。
【Web】全角約物カッコや半角文字列のアキ調整スクリプト
2023年1月15日
約物とか半角文字のアキ調整スクリプトを作ってみた。
以前から気になっていたのですが、印刷用語で約物と呼ばれる『』とか【】は左右にアキがあって、Webドキュメントの中ではどうにも据わりが悪い気がします。このアキを調整する方法もあることはあるのですが、あまり汎用性が高いとは思えません。
半角文字列も、全角文字とはカーニングの仕様が異なるせいか、半角4文字で全角2文字とはいかず、全半角が混在したWebドキュメントは、どうにも文字組が乱雑な印象になってしまいますので、前後にアキ調整が必要なのですが、半角奇数個文字列と偶数個文字列ではアキ調整を変えてやる必要があります。
取り敢えず、約物や半角文字列個別にスタイルを当てるスクリプトを作ってみました。当サイトでも実装済みですので、見た目を確認して使えそうなら使ってみて下さい。
言い訳じみていますが、JavaScriptを1ヶ月程度勉強しただけですので、ツッコミどころは流していただけると助かります。
さて、このスクリプトを作ろうと思ったのも、当サイトのデザインが一因です。デザインの意図なんて閲覧する側は普通意識しませんし、わざわざそれを説明するのもデザイナーの端くれとしてどうかと思うのですが、まあそれはともかく。
Webサイトにおける2カラム構成はありきたりのレイアウトですが、シンプルな印象を作るために全体を囲むブロックの左右はborderなどによる区切りは行わず、テキストやボックス、画像などの行端を揃えて仕切りがあるように見せています。
そのこと自体は別に目新しいものではないのですが、テキストの両端揃え(text-justify)は、半角アルファベットの折り返しや禁則処理を上手くコントロールしないと、スクリーンの解像度によって1行あたりの文字数が変化した時に、文字組が大きく崩れる場合があります。
半角文字列や約物も禁則処理に関わってきますから、改行や1行の文字数をコントロールし、両端揃えでも文字組がなるべく崩れないようにアキ調整スクリプトが必要だった、という話です。
そんな事情で作ったものですから、汎用性はともかく必要性は極めて特殊というか限定的な用途でしかありませんので、似たようなことを考えたことがある人の参考になればいいかな、といったところです。
【Web】Blind/Airの新デザイン
2022年12月12日
まだ生きてたのか、と言われそうなオリンピック更新ですが、五輪は汚職の連鎖で縁起の悪い話です。
前回の更新が2018年7月15日。その前が2014年8月4日。
-

初代まどか中段チェリー全記録(ロンフリ以外)
この8年間、「まどか」に貢いでいたのは否定しませんが。→
ロンフリも22回あります(ぇ
リンク集を見返してみると、半分くらいが消えており、残っているサイトも更新が止まっているサイトが大半だったので、ちょっとしたウラシマ気分、サボリすぎたと言うか時の流れを実感しております。
挙げ句の果てに新しいデザインでサイトを作り直すという更新もどうかと思いますが、このサイトも立ち上げて17年。今回の更新でSNSボタンを追加してみたりスマホ対応にしてみたり、Webの時流に合わせようとはしています。
沈んでいる間に改元で令和となり、WebはSNSやスマホが主流で、HTML5に移行し、IEもサポート終了。IEのフォローがいらないのは何より世間様はコロナ禍やらAIやらDXとやらで大きく動いていると言うのに、自分は変わらずマイペース……とは流石にいきませんでした。
ここ数年は、動画よりも身内のWeb構築を頼まれる頻度が高く、レスポンシブやらPHPやらWordpressでの構築やら、否が応にもWebサイトのデザインと設計の勉強を強いられました。
その結果、自分のサイトのデタラメなコーディングが気になって仕方がなくなり、構造から見直して作り直しました。
2005年にサイトを立ち上げた時は、CSSも満足に使いこなせなかったのですが、少しはマシなコーディングが出来るようになったんでしょうか。
とは言っても、本職のコーディングなんかを見ると、使ったことがないコードとかもたくさんあって、もっと効率の良い設計が出来るんだろうなあと思うと、道は遠いです。
まあ、自分が思い描いた通りにサイトが作れれば、取りあえずは良しとしましょう。
今回のリニューアルを見ると、自分でもデザインや色彩設計の好みが随分と変わったように思いますし、これからどんな活動をしていくのかまだ良く分かってはいません。
動画をやめるつもりはありませんが、AIのプロンプトエンジニアリングとか漫画活動の再開とか、色々と考えていますので、気長に見守っていただけますと幸いです。
次回の更新が新しいサイトデザインになることのないよう、少しは頑張ってみようと思います。
それではまた、無事に会えますように。
SHO-ICHI 拝